Can LLMs like ChatGPT, Copilot, or Claude Replace Text Analysis Software?

Maurice Gonzenbach
Co-Founder and Co-CEO
,Most customer insights teams have faced this question:
“Couldn’t we just use ChatGPT for text analysis?”
This question is not unreasonable. CX managers, market researchers, executives and IT leaders have seen AI capabilities advance rapidly. Large Language Models (LLMs) like ChatGPT, Microsoft Copilot, and Claude are genuinely capable of certain text analysis tasks.
For small companies or quick qualitative analyses, they are a perfectly valid choice.
But for precise, reliable, scalable quantification of unstructured customer feedback (the kind that informs product decisions, tracks experience quality over time, and holds up to scrutiny in a boardroom) they fall short in ways that are structural, not incidental.
By the way, Caplena 💙 LLMs. They power so many of our features, from topic assignment (read how we use LLMs for increased accuracy in this article) to Insight Agent and Smart Columns.
Now let's see exactly when text analysis on ChatGPT, Copilot or Claude can work, when it doesn't, and why these differences matter.
The difference: LLM vs text analysis platform
An LLM is a general-purpose language model that responds to prompts. Brilliantly, but with no memory of your previous analysis, no understanding of your taxonomy, and no consistency between sessions.
A text analysis platform like Caplena is engineered to classify, quantify, and visualize customer feedback data at scale. It includes purpose-built features for codebook management, QA, dashboarding, integrations, alerting, and advanced analytics that an LLM doesn’t provide natively. It incorporates research industry knowledge that solutions built in-house don't have out of the box, and adapts to LLM model updates so you don't have to.
Why everyone thinks LLMs can do Text Analysis
Over the past two years, LLMs have become genuinely impressive at tasks that once required specialized tools:
Summarization: ChatGPT can condense 50 customer reviews into a paragraph in seconds.
Theme extraction: Paste 20 responses into Copilot and it will surface recurring topics.
Sentiment analysis: Ask Claude to rate a comment as positive, negative, or neutral. It will usually get it right.
For a quick gut check on customer sentiment or a one-off assessment, these capabilities are real and useful. The confusion arises because people see these quick tasks (often involving small, clean datasets and simple queries) and then extrapolate: if it can do this for 100 rows, surely it can do it for 20,000?
That extrapolation is where things break down. Uncovering why requires going one level deeper: understanding what “text analysis” actually means when your business depends on collecting customer feedback to drive actionable insights.
When an LLM is enough, when it's not
A simple analogy: Accounting
Here’s a useful way to think about it, borrowed from the world of finance.
A three-person startup can absolutely use Claude to hack a lightweight accounting workflow: have it parse invoices, categorize expenses, and reduce manual data entry in Excel. Clever, fast, and perfectly adequate for their scale.
But ask a company with 100+ employees to run payroll, multi-currency reporting, tax compliance, and audit trails through a patchwork of LLM prompts and spreadsheets. You will quickly see the limits of the improvised approach. At some point, the volume, the stakes, and the need for reliability and auditability demand purpose-built infrastructure.
The same thresholds exist in text analysis.
A small team that needs a qualitative feel for 100 open-ended survey responses twice a year does not require a professional text analysis tool like Caplena (ChatGPT perfectly fits that job).
But if you are running continuous feedback programs across multiple channels, measuring customer satisfaction, tracking topic trends over quarters, and presenting actionable insights to management, then a general-purpose LLM is not the right foundation for that job.
Claude is an amazing tool. But trying to use it for the continuous analysis of high-stakes CX data (or whichever other data) applies the tool outside of its optimal range.
Breaking down the differences
Use this table to guide your decision:
| LLMs | Caplena | |
| Volume |
up to ~200 responses |
thousands to millions |
|
Use case |
one-off exploration |
recurring studies, continuous programs |
|
Output needed |
qualitative overview, summaries | reliable quantification, trend tracking |
| Topic structure |
ad hoc, uncontrolled |
consistent MECE codebook (50–600 topics) |
|
Quality assurance |
none built-in | interactive QA with measurable accuracy |
| Reporting | manual copy-paste, generate and adapt slides / Excel ; follow-up questions take time to compute | shareable interactive reports with slicing and dicing, and quantitative chat functionality |
| Team collaboration | single-user sessions | multi-user, role-based, shared codebooks |
| Data pipeline | manual upload each time | automated ingestion, integrations, alerts |
| Advanced analysis |
not available |
driver analysis, correlations |
| Consistency over time |
results vary by session |
locked codebooks applied consistently |
| Languages | good, but uncontrolled | 100+ languages with controlled output |
| Pricing | token-based pricing (cheap for quick exploration of small studies, potentially expensive and unpredictable for iterative work on large datasets) | predictable credit-based pricing (1 row = 1 credit) with flexible plans for brands and agencies |
The core distinction: LLMs are well-suited for exploration; they are not designed for quantification. The difference is essential. Exploration is how you form a hypothesis. Quantification is how you validate it, track it over time, and build company-wide confidence in the findings.
What happens when you actually try
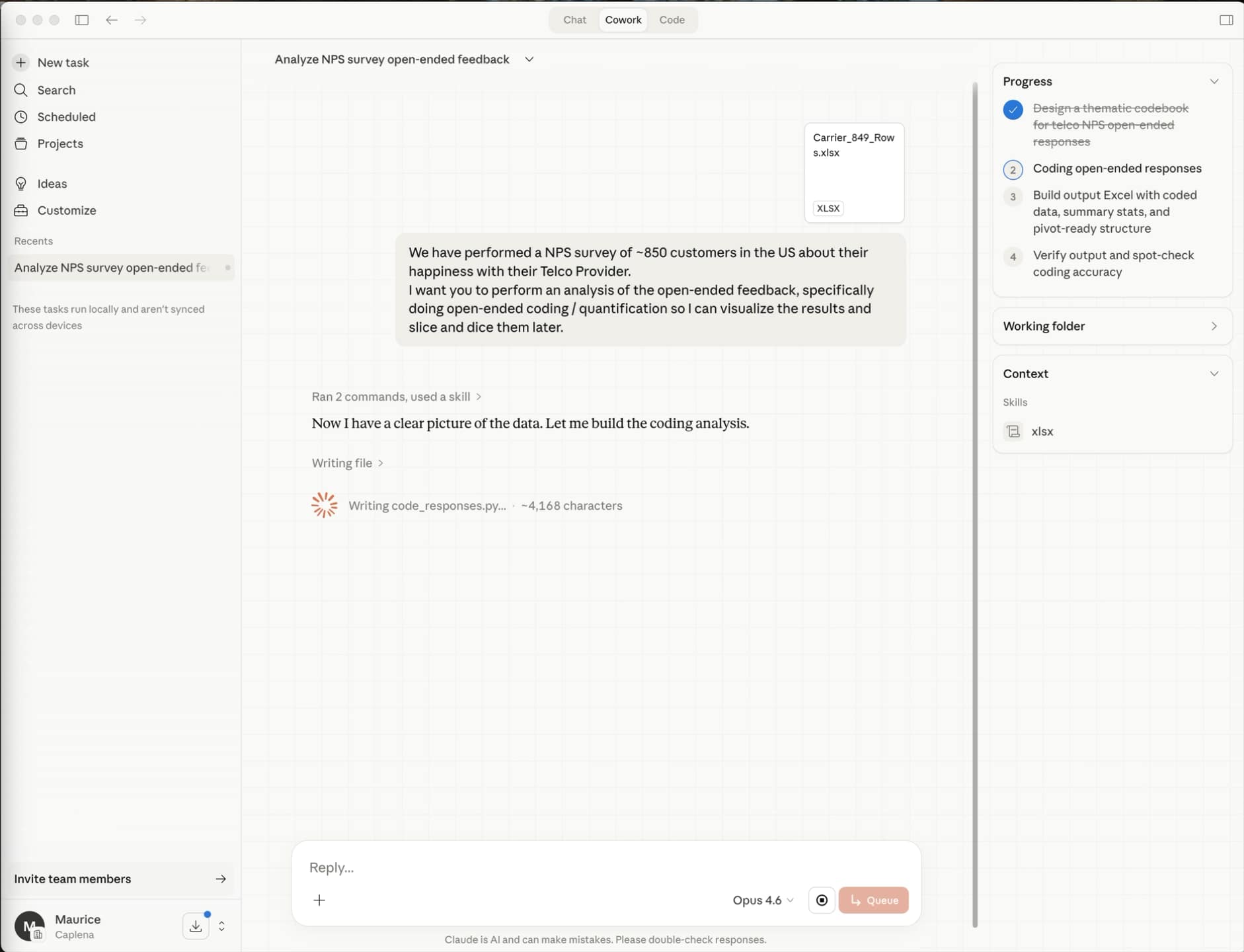
In an internal test, we ran ChatGPT, Copilot and Claude on a simple dataset to evaluate their topic categorization. The dataset included 850 NPS responses for a Telco survey, with a rating, some closed questions and one open-ended question.
We ran parallel sessions in ChatGPT, Copilot and Claude to give each tool every opportunity to succeed. None delivered stakeholder-ready outputs, but they showed their limits in a very instructive way.
Falling back to keyword-matching and legacy NLP methods
One session produced entirely meaningless topics: “Have”, “Years”, “Good”, “Has”, “Verizon”, “Reliable”. These are not topics. They are fragments extracted by keyword frequency, which is essentially the state of Natural Language Processing (NLP) a decade ago. There is a certain irony here: LLMs don’t recognize their own analytical power and defer to legacy NLP methods themselves, whereas professional tools like Caplena have been revolutionized by leveraging LLMs in various ways.
Beyond topic relevance, the consequences also include wrong assignments and a large portion (beyond 30%) of uncoded verbatims, altering output reliability. Some responses including easy to categorize terms like "over priced" were not assigned to topics like "Price / Value".
Another produced outputs that looked more structured, until closer inspection revealed the model had quietly fallen back to a basic keyword-matching Python script, bypassing the LLM entirely.
After more than 20 minutes of prompting, adjusting, burning tokens and re-running across sessions, neither produced anything credible enough to share with a leadership team.
But you don't have to take our word for it. So here is our test using Claude Cowork with Opus 4.6, where the LLM confirms:
using keyword matching
that coding quality is good enough for a directional overview, not for strategic decisions
that its capabilities are "prototype-grade" and teams would be better served with text analytics software
The same dataset, processed in Caplena, took 3.5 minutes and returned a structured output: categorized feedback, sentiment-scored, and built around a coherent codebook as shown in this video.
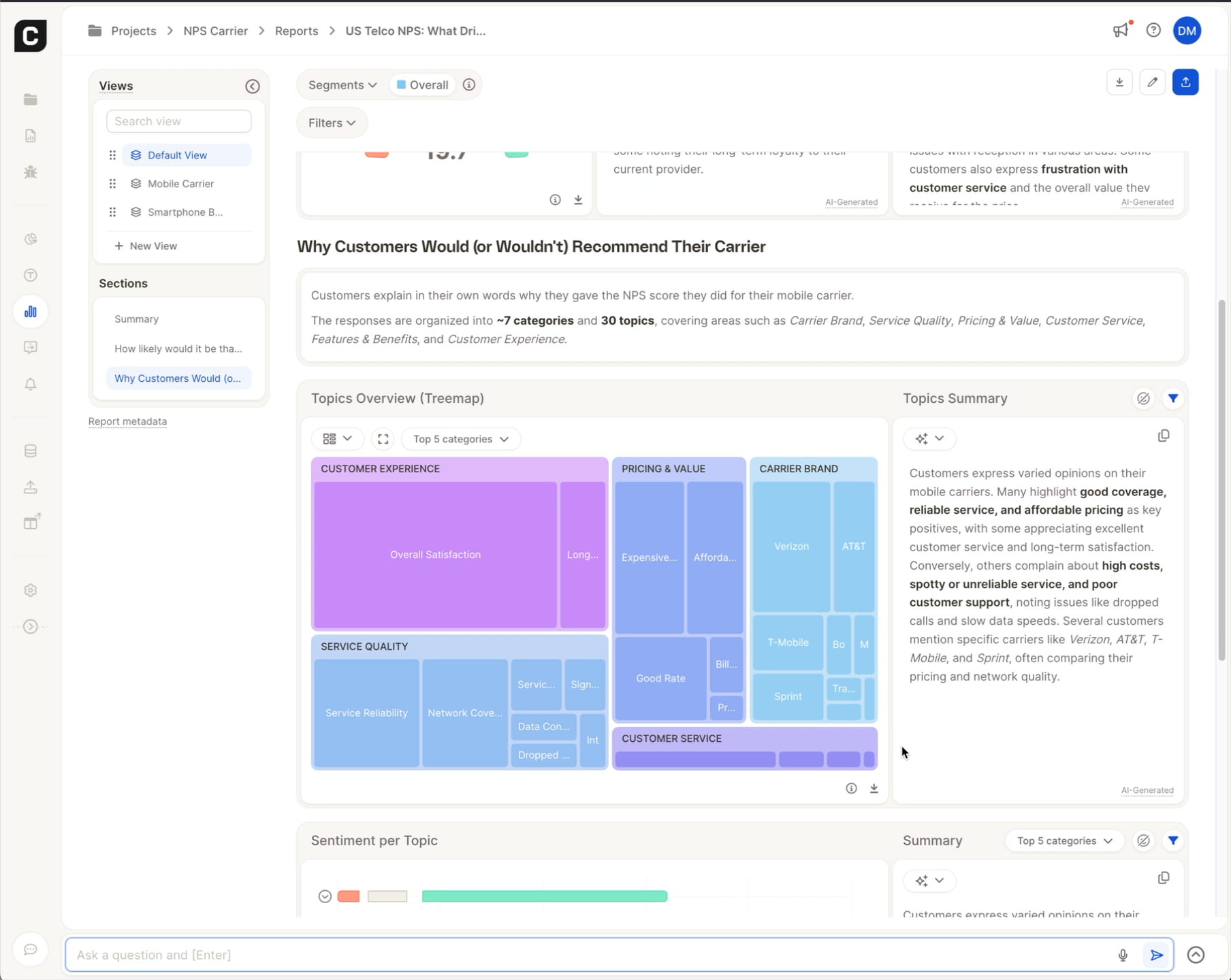
This is not anecdotal. It reflects a fundamental difference in architecture:
LLMs are built to respond to prompts.
Text analysis platforms are built to produce consistent, controlled, reproducible classifications.
What Caplena does that LLMs cannot
1. Build and maintain a structured codebook
The foundation of reliable text analysis is taxonomy. To quantify themes over time, you need a consistent set of topics (typically 50–200) applied identically to every response, across every wave.
Caplena helps you build a MECE (Mutually Exclusive, Collectively Exhaustive) codebook interactively, with a human-in-the-loop approach, then apply it consistently so that your waves are comparable. You can rename, merge, split, and add topics, and our platform applies the retroactive reclassification.
An LLM session has no memory of your previous codebook and no way to enforce consistency.
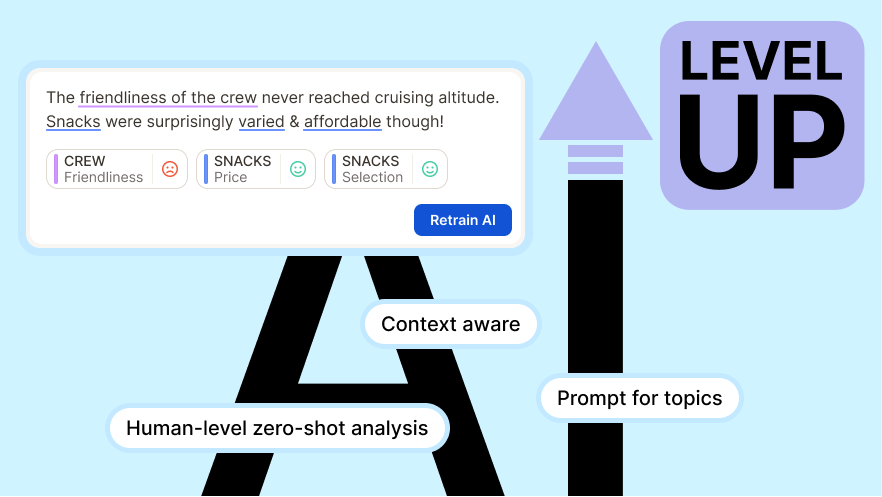
2. Analyze customer feedback with fine-tuned, context-aware AI
Out-of-the-box LLMs don’t know your industry, your brand, or your product names. A telecom customer saying “the signal was garbage after the update” requires contextual understanding to classify correctly under “Network Quality > Mobile Data” rather than “Product Feedback > Software.”
Caplena’s models are trained on feedback data and can be fine-tuned based on your corrections. Caplena learns not only from the open-ended text, but also from the context you provide in your project, column, and topic descriptions. Each adjustment you make automatically improves your future classifications.
3. Measure and iterate on quality
How confident are you in a classification made by a chatbot prompt? You have no way to know.
Caplena provides overall and topic-level quality scores, flags low-confidence assignments for review, and gives you a structured QA workflow to validate and correct results. You can measure quality, track improvements, and demonstrate accuracy to stakeholders. And more importantly, have the foundation to trust your results.
4. Detailed customer sentiment analysis (no prompt engineer required)
In an online review, a customer can be satisfied with the product quality, frustrated with the delivery experience, and neutral about the packaging, all in one sentence.
Asking ChatGPT to reliably perform sentiment analysis at the topic level, at scale, with a fixed output schema requires lots of prompt engineering for every feature (and redoing it every time the LLM is updated).
Caplena takes over the painstaking part of reliably applying the LLM to thousands of rows so you don’t have to. You get topic-level sentiment assignments out of the box, which you can control and fine-tune with no headache.
5. Query and visualize at scale in real time
Imagine filtering 500,000 responses by country, product type, NPS segment, customer sentiment, and topic and getting a result in under two seconds. Caplena is built on infrastructure designed for this. LLMs have context window limits, no persistent state, and no query layer. Feeding them a 500k-row CSV is not an option.
6. Built-in, advanced customer experience analytics and visualisations
Driver analysis, correlation chord diagrams, and trend visualization without additional development. All accessible from Caplena and inside everyday apps like Teams and Slack.
With an LLM, every one of these would require custom scripting, manual data exports, and ongoing maintenance.
7. An intuitive interface that puts valuable insights in everyone’s hands
An LLM session produces output for one user, in one language, at one moment in time.
Caplena produces a shared workflow across teams and markets and a living picture of the voice of the customer that an entire team can explore.
Dashboards are designed to be navigated by everyone in the organization, from the CX director to the store manager. Users can drill from a topic category trend down to the individual verbatim that drove it, in its original language.
8. Smart Columns: data enrichment without a data scientist
Customer feedback datasets are rarely clean.
LLMs can automate the preprocessing of customer feedback data to remove noise. standardize formats or extract entities in text data. But this involves custom scripts.
Caplena solves that gap with Smart Columns: a guided process that allows any user to cleanse and enrich raw data directly within Caplena. All without writing a line of code or filing a request with a data team.
The result: faster time-to-insight, fewer bottlenecks, and deeper findings.
The engine vs. the car
A useful way to think about the relationship: an LLM is an engine. Caplena is a fully-functioning car.
An engine is impressive. It is the core technology that makes everything possible. But you cannot drive an engine to work. You need a chassis, a steering wheel, a dashboard, seatbelts, GPS, and the infrastructure of a road. Without all of that, the engine has potential, but it cannot actually be used.
Caplena wraps that engine with everything a team needs to go from raw feedback to company-wide decisioning: an intuitive interface, structured QA workflows, collaboration features, alerts, integrations, stakeholder-ready reporting views and insight agent access.
You could assemble a car yourself. Some organizations choose building in-house. Based on typical development timelines, such internal projects easily take 3-9 months in initial development alone before you get something that works, And it still will only have a fraction of the features of a platform built and refined over the years. Plus you need to consider ongoing maintenance.
And then there is a layer beyond the car itself: the road network it connects to.
MCP servers: a safer road to agentic AI
Enterprises are not just running analyses anymore. They are building agentic workflows where AI clients retrieve data, run logic, and surface recommendations automatically. The bottleneck in those workflows is not the agent. It is the reliability of what the agent reads.
Caplena's MCP (Model Context Protocol) server is designed precisely for this context:
A prompt sent to a raw LLM returns a response. A query sent to Caplena's MCP server returns something fundamentally different: structured, QA-validated, statistically consistent analysis that any downstream system can trust and act on.
Multi-source connectivity: feedback from surveys, CRM, support tickets, social media comments and online review sites unified before it ever reaches an agent
Text analysis and statistical backbone: consistent topic and sentiment assignments, and calculations (trend data, driver analysis, etc.) your AI workflows can depend on
Enterprise-ready: infrastructure built for scale, from creating slides presenting findings from the latest NPS wave to enriching insights with web search and other data sources
For teams building on top of AI clients like Claude or Copilot: Caplena is not another tool to prompt. It is what makes those prompts trustworthy to find meaningful insights.
Risks for customer feedback analysis
The cost of using the wrong tools isn’t just inefficiency. Neither are sweat and tears developing and maintaining internal builds. It lies in bad decisions made from bad data.
No consistency, no reliable trends
If your topic categories shift from one session to the next — because you re-ran the prompt, changed the wording — you can’t track trends. And if you can’t track trends, you can’t demonstrate the value of your feedback program to the business.
No audit trail creates accountability gaps
When a VP asks “how did you determine that 34% of customers mentioned billing issues?”, the answer cannot be “I pasted it into ChatGPT and it said so.” Purpose-built platforms maintain an audit trail of every classification decision, every codebook change, and every QA action.
Scale hides problems
An LLM can analyze 50 responses and miss nothing. At 50,000, sampling bias, prompt drift, and context window limits mean you’re not analyzing your data: you’re analyzing a fragment of it in ways you can’t fully control or verify.
Manual workflows create organizational debt
Every hour your team spends copying results out of ChatGPT, reformatting them, and building slides manually is time not spent on interpretation, strategy, and action. Over months, this accumulates into a significant overhead that a purpose-built tool eliminates.
Sensitive data exposure
Pasting customer feedback into a public LLM interface creates data governance and privacy risks. Purpose-built platforms offer contractual data processing agreements, GDPR compliance frameworks, and infrastructure that keeps sensitive data protected.
The right tool for the right job
This isn’t a zero-sum competition. LLMs like ChatGPT, Copilot, and Claude are genuinely useful, including within Caplena itself! The question is not whether LLMs are good, but whether they are sufficient for your specific use case.
For exploratory work like getting a quick qualitative impression, scanning a handful of responses, prototyping an analysis before committing to a methodology, a general-purpose AI tool is fast, accessible, and up to the task.
For company-wide programs that inform product decisions, track customer experience across business units, or require findings that can be defended in front of a leadership team, the requirements change dramatically. Precision, consistency, auditability, and scale are non-negotiable. That is the problem Caplena is built to solve.
This is why Caplena integrates with Microsoft Copilot, Claude and ChatGPT, so you can interrogate your data and surface structured, QA'd insights from Caplena directly within the interface your team already uses. And through Caplena’s MCP (Model Context Protocol) server, AI agents can query your feedback data, run analyses, and retrieve results programmatically, making Caplena a native part of your agentic AI workflows.
The goal isn’t replacement. It’s using the right layer for each part of the job.
Curious to see the difference?
Are you analyzing open-ended feedback in ChatGPT, Copilot, or Excel?
Or are you evaluating whether a text analysis platform is worth it for your organization?
We’d be glad to walk you through a live comparison on your own data.
- The difference: LLM vs text analysis platform
- Why everyone thinks LLMs can do Text Analysis
- When an LLM is enough, when it's not
- What happens when you actually try
- What Caplena does that LLMs cannot
- The engine vs. the car
- MCP servers: a safer road to agentic AI
- Risks for customer feedback analysis
- The right tool for the right job
Related blog posts


A Stoic Breakdown: Sentiment Analysis
Unless you are a psychopath, humans are by nature emotional beings. Anger, sadness, happiness, and love are emotions that almost every human has felt. Nowadays, we have a plethora of emotional AI detection methods at hand. Sentiment analysis is one of the most used methods.





A Stoic Breakdown: Sentiment Analysis
Unless you are a psychopath, humans are by nature emotional beings. Anger, sadness, happiness, and love are emotions that almost every human has felt. Nowadays, we have a plethora of emotional AI detection methods at hand. Sentiment analysis is one of the most used methods.