Meet our new AI: Human-level accuracy in coding open-ends with LLMs

Justin Lo
AI NLP Engineer at Caplena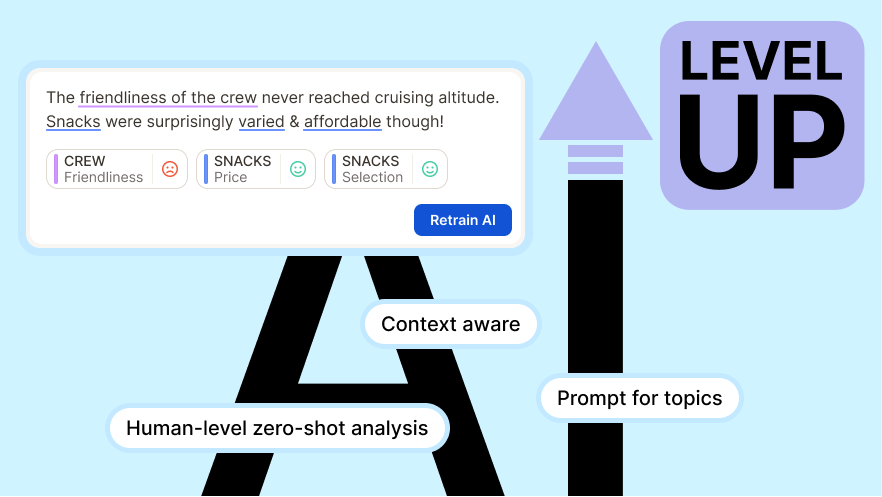
Classifying and understanding thousands of open-ended responses is an incredibly daunting task for humans. Today, it has become an obvious use case for AI to solve - yet output quality may vary.
At Caplena, we relentlessly innovate to achieve human-level analysis out of the box. Since 2017, we have used machine learning to turn qualitative responses into meaningful insights. We have continuously been at the forefront of developments, starting with Convolutional Neural Networks, over Bert up to custom transformer models we trained from scratch. With the advent of Large Language Models (LLMs), we saw new opportunities for greater flexibility, stronger contextual understanding, and improved performance.
But using LLMs isn’t just about plugging it into GPT5 or Gemini and using their output. Instead, LLMs require careful design and techniques to produce results that are accurate, repeatable and reliable to our users.
In the last months, we have rolled out a new version of our AI model relying on LLMs for topic assignment.
The result? Our customers see significantly increased quality in 0-shot analysis (the initial topic and sentiment analysis done by our AI, before any fine-tuning).
In this post, we openly share how we got there. We will cover:
the benefits we observed from incorporating LLMs
the challenges we have faced along the way
how we have iterated over time to integrate LLMs in a way that is suitable for open-ended coding.
the improvements we have observed
If you're an insights pro who is curious about our tech, or a data scientist exploring whether to build such solution in-house or select a trusted partner, this article is for you.
Why LLMs for open-ended coding?
While traditional Machine Learning models have served us well over the past few years, LLMs offer a distinct advantage that changes our approach towards open-ended coding.
Reason 1: Concise and Informative Results
LLMs are trained on large volumes of text. They can better understand the patterns and nuances of language. In a challenging task such as open-ended coding, having an AI that can concisely and accurately determine a text’s intent can improve the quality of the output that we provide to our users.
This is especially relevant when there are subtle distinctions between topics within a topic collection. For example, we often work with large topic collections, some of which are closely related or nuanced. With traditional machine learning (ML) models, we typically query each topic independently, asking the model if the text individually crosses a threshold to be assigned to that individual topic. However, with fine-grained topics, this can lead to over-assignment. The model is unable to evaluate when there is a more accurate topic that should be assigned instead.
Traditional Machine Learning Assignment:
In this example, the traditional ML model seems to believe that damaged packaging can be represented by a negative product quality. Without the knowledge of what the other topics were, this may have been an acceptable assignment to demonstrate the damaged packaging. However, this is not fully accurate when there is already the better ‘packaging quality’ topic.
LLM-based Topic Assignment:
LLMs allow us to present the full list of topics at once. This enables the model to see an overview of how topics relate to each other and produce more concise and relevant outputs.
Reason 2: Continuous Improvements
LLMs advance at a rapid pace, and we can adopt those changes to improve our models almost instantaneously. As LLMs learn to understand the nuances of the human language better, they not only improve the accuracy of our topic assignments but also have a better understanding of the evolving knowledge in our world. This allows our AI to remain relevant and effective at categorizing feedback that we receive.
Reason 3: Contextual Understanding
A major benefit of LLMs is the ability to inject context into the AI. At Caplena, we help classify a diverse set of responses, each project coming with its own business context and use case. By using a LLM, we can include this information into the decision-making process, improving the quality of the AI output.
By default, the AI will judge information based on an objective context. For example, when a respondent to an employee satisfaction survey kindly suggests having “a chance to interact more with teammates”, it may be seen as a neutral statement. Or if a text appears to suggest specific development courses, the AI may view it as a positive sentiment that demonstrates the company’s openness to career development.
Topic classification without providing any contextual information:
When adding some context, such as a description of the project, our perspective on these statements will be different. This is evident from the change in the LLM’s sentiment classification and topic assignments once we provide additional contextual information.
Topic classification with additional context about the dataset:
3 Challenges with LLM topic classification
Using an LLM sounds simple – we just provide all the topics and ask the LLM to perform topic classification, right? Unfortunately, this is not the case.
LLMs are trained to converse in open-ended natural language conversations, but that creates a lot of disorganisation and unpredictability. Dealing with these options and uncertainty remains an obstacle in deploying LLMs into an application.
🫠 Challenge 1: Hallucinations, gullibility & reproducibility
LLMs are designed to be creative, engaging in conversations that feel natural and fluid, but reliability remains a core challenge. They may hallucinate false information, display jagged intelligence by excelling at complex reasoning yet failing on trivial logic (like our friend, Bart in the photo👇), and produce inconsistent outputs across identical prompts. Such instability can severely impact longitudinal analyses like tracking studies, where reproducibility is essential.
Unstructured, conversational data that is difficult to process:
🤯 Challenge 2: Overwhelming options
With the open-ended nature and flexibility of LLMs, there are many options available to us. There is no fixed method to get consistent results; we can employ a variety of techniques and models to alter the output of the LLM. Although this may seem like a good thing, it creates a plethora of decisions. For instnace, should I use Gemini, GPT-5, or Claude? What temperature should I set? How should I format my inputs to balance cost and quality?
|
Example of questions to consider |
|
Each decision comes with tradeoffs in performance, cost, time, and adaptability. To a user trying to perform analysis, these options may result in hinderance to their workflow. Without careful experimentation, this may even result in unintended results that may limit the potential of the analysis.
🤔 Challenge 3: Limited interpretability
When an LLM classifies a text into various topic assignments, we have limited understanding of why it decided on that classification. Instead, we have to believe that the LLM is making accurate decisions on the full dataset. This makes it more challenging to debug any errors within the LLM, and hence more difficult for people to trust it.
LLMs are akin to wild horses that need to be tamed. When designing our solution at Caplena, we experimented with numerous methods and options, finding a way to mitigate the challenges of using a LLM while ensuring that we can reap the benefits it provides.
In the next section, we provide a sneak peek into the experiments we have conducted and the rationale behind the decisions in constructing our desired LLM model.
How we built our AI model
Selecting a LLM for open-ended coding is not just about choosing the ‘largest’ or ‘most popular’ model and hoping that it works. There are many dimensions that one must consider and conduct rigorous experiments with.
Proprietary or Open-Source Models?
When deciding to use LLMs, one of the core questions that arose was the kind of model that should be employed. To address this, we first compared the benefits of using a proprietary model vs an open-sourced model.
| Features |
Proprietary model |
Open-Source models |
|
Constant upgrades |
✅ Easily inherit improvements made to the LLM |
❌ Requires re-training & deployment |
|
Fine-tuning capability |
⚠️ Non-existent, or limited & expensive through an API |
✅ Fine-tuning possible |
|
Maintenance |
✅ Hosting & scaling is handled by 3rd party |
❌ Need to manage infrastructure personally |
|
Data privacy |
✅ Available via terms with 3rd party |
✅ Can be fully controlled internally |
|
Cost |
⚠️ API Pricing (variable) |
⚠️ High fixed cost, which can be cheaper after setup |
Proprietary models provide quick access to improvements.
If there are any changes that we need to experiment with, they provide quick API calls that can be tested. In addition, with the correct architecture set up, we can easily change between models to take advantage of any advancements made. We also conducted numerous experiments between different kinds of proprietary models to better understand the capabilities of each of them relative to their speed and cost.
The main disadvantage of proprietary models is the restrictions on fine-tuning.
Hence, we explored alternative methods that we could utilize to improve the performance of the model for our use case.
In the following section, we discuss a subset of the methods we have experimented with and describe how we have integrated them with our new AI.
3 Alternatives to Full Fine-tuning
1️⃣ Embeddings + Retrieval Augmented Generation (RAG)
Why we explored it: That method piqued our interest due to our large corpus of data we have available. We could store different kinds of reference data as vector embeddings. This could be used in various areas.
For example, when a new topic classification is required, the AI could retrieve data that is likely relevant to it and try to perform a similar classification (similar to K-Nearest Neighbours).
Alternatively, the embeddings could be used to determine which training examples may be useful to provide to the LLM as additional context. In theory, the use of embeddings provides the model immediate access to domain-specific examples without any retraining required.
How RAG works:
What we learned: upon experimentation, we discovered that this method is not well-suited to open-ended responses as they contain multiple topics in a nuanced context. By converting them into embeddings, the model lost some subtle distinctions and ended up being unable to accurately distinguish between various texts. Despite trying mitigation techniques, the performance of the RAG showed limitations for our context and hence was not desirable.
2️⃣ In-context Learning
Why we explored it: we considered it as alternative to retraining the full model via fine-tuning. The idea is that while performing inference using the base model, we include within the prompt some examples of texts and their corresponding topic assignments. This method allows the model to “learn” on the fly.
This method is simple, easy to maintain and does not require any retraining, while utilizing the training data we have available. This helps the model to understand the patterns of the human labeler and tailor its responses towards what the user desires.
How in-context learning example works:
What we learned: with in-context learning, one can provide a limited context window to an LLM. With limited tokens to write within the prompt, we cannot include every reviewed example, and poorly chosen examples can hurt performance.
Hence, after careful experimentation, we devised a selection system that chooses the best examples to provide the LLM during its inference, allowing it to learn the most from the limited data that we can provide.
3️⃣ Chain-of-thought prompting + Reasoning
Why we explored it: to improve the classification that the LLM provided, we had to be innovative about how we encourage the LLM to provide us with more accurate topic assignments.
With “chain-of-thought” prompting, we prompt the model to write out some intermediate reasoning steps before reaching its conclusion. This allows the model to make a more deliberate and consistent decision and reduce the likelihood of random topic assignments.
This concept has been exemplified with the recent surge of “reasoning models” available. In many new models, models spend some time “thinking” about the problem before producing an output for the user.
What we learned: when we experimented with these reasoning models, we found that there was minimal performance gain. Upon conducting further analysis on the reasoning chains, we discovered that out-of-the-box reasoning models produce a lot of irrelevant “thoughts” that are not very specific and seemingly end up functioning as noise. Not only does this hinder the potential of the LLM, but it also incurs unnecessary additional time and cost while producing these “thinking tokens”.
Therefore, we experimented with various reasoning models available. We researched how the models were trained to structure their thoughts and came up with our own instructions to get the model to produce focused, minimal reasoning chains that directly addressed our requirements. By doing this, we not only ensured that we did not waste unnecessary time producing unwanted tokens but also provided a structured manner to improve the classification made by the LLM.
☝️ Top: Default ‘reasoning chain’ (very verbose, does not directly address the text )
Bottom (Caplena): Sample shortened and focused reasoning chain
How much have LLMs improved Caplena's AI?
After numerous experiments with an LLM-based approach, we found that it not only sounded good on paper, but also verifiably improved our results.
To measure the quality of assignments, we use the F1 score against a human-annotated dataset to balance between precision (how often the AI is correct when assigning a topic) and recall (how often the AI correctly finds the actual topics). This ensures we account for cases of missing out correct topics, as well as incorrectly assigning topics.
We conducted experiments on a representative dataset, consisting of data from different contexts:
a mix of simple and complex texts
and data of different languages.
In our experiments, without providing any manually reviewed rows as training data (0-shot performance), we observed that
the traditional Machine Learning (ML) model achieved an F1 score of 0.441
our carefully designed LLM-based approach scored 0.610!
This is an over 38% increase from our previous AI.
Conclusion
Our new LLM approach focuses on making AI useful, transparent, and adaptable for our users.
In Caplena, users can define project and topic descriptions to give the AI the right context. This keeps the process transparent and ensures topic assignments fit their needs. Still, the quality of results depends on a well-structured, MECE codebook, as even the best AI struggles with weakly defined topics.
Topic assignment is an iterative process. After the first pass, users can refine topics or descriptions to capture missing nuances. In tracker studies, where topics evolve over time, Caplena flags potential new themes and lets users re-trigger the AI to keep analyses up to date.
Our approach combines the strengths of LLMs with reliability and trust. The built-in AI score gives a clear confidence measure for every topic assignment. As models improve, we’ll continue refining our methods to deliver consistent, high-quality results.
Related blog posts



A Stoic Breakdown: Sentiment Analysis
Unless you are a psychopath, humans are by nature emotional beings. Anger, sadness, happiness, and love are emotions that almost every human has felt. Nowadays, we have a plethora of emotional AI detection methods at hand. Sentiment analysis is one of the most used methods.





A Stoic Breakdown: Sentiment Analysis
Unless you are a psychopath, humans are by nature emotional beings. Anger, sadness, happiness, and love are emotions that almost every human has felt. Nowadays, we have a plethora of emotional AI detection methods at hand. Sentiment analysis is one of the most used methods.